[Updated December 30, 2019: You can read more about the package, new functionality, and other approaches to SEM in my online book (work-in-progress): https://jslefche.github.io/sem_book/]
[Updated October 13, 2015: Active development has moved to Github, so please see the link for the latest versions of all functions: https://github.com/jslefche/piecewiseSEM/]
Nature is complex. This seems like an obvious statement, but too often we reduce it to straightforward models. y ~ x and that sort of thing. Not that there’s anything wrong with that: sometimes y is actually directly a function of x and anything else would be, in the words of Brian McGill, ‘statistical machismo.’
But I would wager that, more often that not, y is not directly a function of x . Rather, y may be affected by a host of direct and indirect factors, which themselves affect one another directly and indirectly. If only there was someway to translate this network of interacting factors into a statistical framework to better and more realistically understand nature. Oh wait, structural equation modeling.
What is structural equation modeling?
Structural equation modeling, or SEM for short, is a statistical framework that, ‘unites two or more structural models to model multivariate relationships,’ in the words of Jim Grace. Here, multivariate relationships refers to the sum of direct and indirect interactions among variables. In practice, it essentially strings together a series of linear relationships.
These relationships can be represented using a path diagram with arrows denoting which variables are influencing (and influenced by) other variables. Take a very simple path diagram:

Which is described by the equation: Y ~ X1 + X2.
Not consider a different arrangement of the same variables:
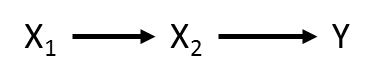
Which is now described by two equations: X2 ~ X1 and Y ~ X2. These two equations make up the SEM.
Assumptions of SEM
There are a few important points to make:
(1) As I pointed out, I’m talking about linear relationships. There are ways to integrate non-linear relationships into SEM (see Cardinale et al. 2009 for an excellent example), but for the most part, we’re dealing with straight lines.
(2) Second, we assume that the relationships above are causal. By causal, I mean that we have structured our models such that we assume X1 directly affects Y , and not the other way around. This is a big leap from more traditional statistics where we the phrase ‘correlation does not imply causation’ is drilled into our brains. The reason we can infer causative relationships has to do with the underlying philosophy of SEM. SEM is designed principally to test competing hypotheses about complex relationships.
In other words, I might hypothesize that Y is directly influenced by both X1 and X2 , as in the first example above. Alternately, I might suspect that X1 indirectly affects Y through X2 . I might have arrived at these hypotheses through prior experimentation or expert knowledge of the system, or I may have derived them from theory (which itself is supported, in most cases, by experimentation and expert knowledge).
Either way, I have mathematically specified a series of causal assumptions in a causal model (e.g., Y ~ X1 + X2 ) which I can then test with data. Path significance, the goodness-of-fit, and the magnitude of the relationships all then have some bearing on which logical statements can be extracted from the test: X1 does not directly affect Y , etc. For more information on the debate over causation in SEMs, see chapters by Judea Pearl and Kenneth Bollen.
(3) Third, in the second example, we have not estimated a direct effect of X1 on Y (i.e., there is no arrow from X1 to Y , as in the first example). We can, however, estimate the indirect effect as the product of the effect of X1 on X2 and the effect of X2 on Y . Thus, by constructing a causal model, we can identify both direct and indirect effects simultaneously, which could be tremendously useful in quantifying cascading effects.
Traditional SEM attempts to reproduce the entire variance-covariance matrix among all variables, given the specified model. The discrepancy between the observed and predicted matrices defines the model’s goodness-of-fit. Parameter estimates are derived that minimize this discrepancy, typically using something like maximum likelihood.
Piecewise SEM
There are, however, a few shortcomings to traditional SEM. First, it assumes that all variables are derived from a normal distribution.
Second, it assumes that all observations are independent. In other words, there is no underlying structure to the data. These assumptions are often violated in ecological research. Count data are derived from a Poisson distribution. We often design experiments that have hierarchical structure (e.g., blocking) or observational studies where certain sets of variables are more related than others (spatially, temporally, etc.)
Finally, traditional SEM requires quite a large sample size: at least (at least!) 5 samples per estimated parameter, but preferably 10 or more. This issue can be particularly problematic if variables are nested, where the sample size is limited to the use of variables at the highest level of the hierarchy. Such an approach drastically reduces the power of any analysis, not to mention the heartbreak of collapsing painstakingly collected data.
These violations are dealt with regularly by, for instance, fitting generalized linear models to a range of different distributions. We account for hierarchy by nesting variables in a mixed model framework, which also alleviates issues of sample size. However, these techniques are not amenable to traditional SEM.
These limitations have led to the development of an alternative kind of SEM called piecewise structural equation modeling. Here, paths are estimated in individual models, and then pieced together to construct the causal model. Piecewise SEM is actually a better gateway into SEM because it essentially is running a series of linear models, and ecologists know linear models.
Evaluating Fit in Piecewise SEM: Tests of d-separation
Piecewise SEM is a more flexible and potentially more powerful technique for the reasons outlined above, but it comes with its own set of restrictions. First, estimating goodness-of-fit and comparing models is not straightforward. In traditional SEM, we can easily derived a chi-squared statistic that describes the degree of agreement among the observed and predicted variance-covariance matrices. We can’t do that here, because we’re estimating a separate variance-covariance matrix for each piecewise model.
Enter Bill Shipley, who derived two criteria of model fit for piecewise SEM. The first is his test of d-separation. In essence, this test asks whether any paths are missing from the model, and whether the model would be improved with the inclusion of the missing path(s). To understand this better, we must first define a few terms.
Shipley’s perspective is based on what are known as directed acyclic graphs (DAG), which are essentially path diagrams, as above. Two variables are considered causally dependent if there is an arrow between them. They are causally independent if there is not an arrow between them. Consider the following example:
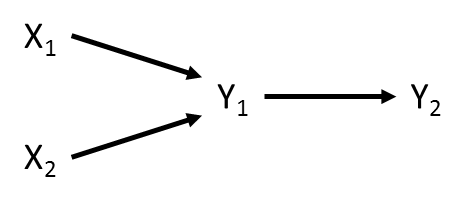
X1 is causally independent of Y2 because no arrow exists between them.
However, X1 indirectly influences Y2 via Y1 . Thus, X1 is causally independent of Y2 conditional on Y1 . This is an important distinction, because it has implications for the way in which we test whether the missing arrow between X1 and Y2 is important.
A test of directional separation (d-sep) asks whether the causally independent paths are significant while statistically controlling for variables on which these paths are conditional. To begin, one must list all the pairs of variables with no arrows between them, then list all the other variables that are direct causes of either variable in the pair. These pairs of independence claims, and their conditional variables, forms the basis set.
For the example above, the basis set is:
X1andX2X1andY2, conditional onY1X2andY2, conditional onY1
The basis set can then be turned into a series of linear models:
X1 ~ X2X1 ~ Y2 + Y1X2 ~ Y2 + Y1
As you can see, we include the conditional variables ( Y1 and Y2 ) as covariates, but we are interested in those missing relationships (e.g., X1 ~ X2). We can run these models, and extract the p-values associated with the missing path, all the while controlling for Y1 and/or Y2. From these p-values, we can calculate a Fisher’s C statistic using the following equation:
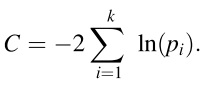
which follows a chi-squared distribution with 2k degrees of freedom (where k = the number of pairs in the basis set). Thus, if a chi-squared tests is run on the C statistic and P < 0.05, then the model is not a good fit. In other words, one or more of the missing paths contains some useful information. Conversely, if P > 0.05, then the model represents the data well, and no paths are missing.
Evaluating Fit in Piecewise SEM: AIC
SEM is often implemented in a model testing framework (as opposed to a more exploratory analysis). In other words, we are taking a priori models of how we think the world works, and testing them against each other: reversing paths, dropping variables or relationships, and so on. A popular way to compare nested models is the use of the Akaike Information Criterion (AIC). Shipley has recently extended d-sep tests to use AIC. It’s actually quite straightforward:
![]()
The formula should look quite familiar if you’ve ever calculated an AIC. In this case, the gobbledy gook in brackets is simply C, above. In this case, however, K is not the number of pairs in the basis set (that’s little k, not big K). Rather, K the number of parameters estimated across all models. The additive term can be modified to provide an estimate of AIC corrected for small sample size (AICc).
An Example from Shipley (2009)
In his 2009 paper, Shipley sets forth an example of tree growth and survival among 20 sites varying in latitude using the following DAG:
![]()
Happily for our purposes, Shipley has provided the raw data as a supplement, so we construct, test, and evaluate this SEM. In fact, I’ve written a function that takes a list of models, performs tests of d-sep, and calculates a chi-squared statistic and an AIC value for the entire model. The function alleviates some of the frustration with having to derive the basis set–an exercise at which I have never reliably performed–and then craft each model individually, which can be cumbersome with many variables and missing paths. You can find the most up to date version of the function on GitHub.
First, we load up the required packages and the data:
Then we load the data and build the model set:
# Load required libraries library(lmerTest) library(nlme) data(shipley2009) shipley2009.modlist = list( lme(DD~lat, random = ~1|site/tree, na.action = na.omit, data = Shipley), lme(Date~DD, random = ~1|site/tree, na.action = na.omit, data = Shipley), lme(Growth~Date, random = ~1|site/tree, na.action = na.omit, data = Shipley), glmer(Live~Growth+(1|site)+(1|tree), family=binomial(link = "logit"), data = shipley2009) )
Finally, we can derive the fit statistics:
sem.fit(shipley2009.modlist, shipley2009)
which reveals that C = 11.54 and P = 0.48, implying that this model is a good fit to the data. If we wanted to compare the model, the AIC score is 49.54 and the AICc is 50.08.
*These values differ from those reported in Shipley (2009) as the result of updates to the R packages for mixed models, and the fact that he did not technically correctly model survivorship as a binomial outcome, as that functionality is not implemented in the nlme package. I use the lmerTest package at it returns p-values for merMod objects based on the oft-debated Satterthwaite approximation popular in SAS, but not in R.
Shortcomings of Piecewise SEM
There are a few drawbacks to a piecewise approach. First, the entire issue of whether p-values can be meaningfully calculated for mixed models rears its ugly head once again (see famous post by Doug Bates here). Second, piecewise SEM cannot handle latent variables, which are variables that represent an unmeasured variable that is informed by measured variables (akin to using PCA to collapse environmental data, and using the first axis to represent the ‘environment’). Third, we cannot accurately test for d-separation in models with feedbacks (e.g., A -> B -> C -> A). Finally, I have run into issues where tests of d-separation cannot be run because the model is ‘fully identified,’ aka there are no missing paths. In such a model, all variables are causally dependent. One can, however, calculate an AIC value for these models.
Get to it!
Ultimately, I find SEM to be a uniquely powerful tool for thinking about, testing, and predicting complex natural systems. Piecewise SEM is a gentle introduction since most ecologists are familiar with constructing generalized linear models and basic mixed effects models. Please also let me know if anything I’ve written here is erroneous (including the code on GitHub!). These are complex topics, and I don’t claim to be any kind of expert! I’m afraid I’ve also only scratched the surface. For an excellent introductory resource to SEM, see Jarrett Byrnes’ SEM course website–and take the course if you ever get a chance, its fantastic! I hope I’ve done this topic sufficient justice to get you interested, and to try it out. Check out the references below and get started.
References
Shipley, Bill. “Confirmatory path analysis in a generalized multilevel context.” Ecology 90.2 (2009): 363-368.
Shipley, Bill. “The AIC model selection method applied to path analytic models compared using a d-separation test.” Ecology 94.3 (2013): 560-564.
Shipley, Bill. Cause and correlation in biology: a user’s guide to path analysis, structural equations and causal inference. Cambridge University Press, 2002.

Thanks for this really nice introduction to your recently developed package and piecewise SEM! It’s nice to see more user-friendly approaches being developed for Bill Shipley’s D-sep test. Do you know if it is possible to extend this method to use models such as MRM’s (multiple regression on distance matrices) that are based on permutation tests of significance? And if so, any chance this could be eventually included in the piecewiseSEM package?
Hi Andrew, Shoot me an email and we can discuss. Cheers, Jon
Hi Jon,
I am just interested in the outcome of the discussion above: are you aware of a way to include distance matrices (e.g. functional, phylo.) into SEMs, as you can do in MRMs or Mantel tests? Taking principal coordinates (or axes from a PCA) wouldn’t be a solution for me, as I am interested doing an SEM based on distances only.
Any hints are welcome.
Thanks,
Oliver
Hi Oliver, Drop me an email and we can coordinate. The short answer is: its complicated. The long answer is: its doable, but may be extraordinarily difficult depending on the complexity of your model. The issues are primarily that the MRM() function in the ecodist package does not return a S3 / S4 model object, which means it does not play nice with piecewiseSEM. Cheers, Jon
Hi Jon, thanks for piecewiseSEM. I have been working on it. However, when I try to use it with my data I get some errors. These errors happen when I use random effects (lme, lmer, or glmer..). When I use lm() function and omit the random effects everything works fine…
If I use the lmer(), I also get an error, the p-values can not be
any thoughts?
Do you think I should test for missing paths by hand and use the lmer results?
I can sent you me code if necessary..
Thanks
Jaime
#################################
> sem.fit(Zoo_pSEM_randomList, Zoo)
| 0%
Error in MEEM(object, conLin, control$niterEM) :
Singularity in backsolve at level 0, block 1
Hi Jaime, It seems like you have a convergence error. This is, in my experience, far more likely with lme4 (and lmerTest) than with other packages, including the base lm() and lme() from the nlme package. You can try to relax the criteria for convergence using the lmerControl() option in the model list. Alternately, I recommend fitting the model using lme(), unless you have a non-normal response. Shoot me an email if you have any further questions or issues! Cheers, Jon
Hi Jon, thanks for the answer… I have tried to relax the models and thinks look better, however, I still have some problems with the random effects… whenever I want to use the random effects, I have to the same fixed variables (factors from an experiment) in each model… so, what I did was a lm(X~random.effects) and use the residuals as response… and switch to lm() instead of lmer or lme. I will keep playing with it and drop you a mail… Thanks alot…
Jaime
Hi Jon, Thanks for this! It seems very suited to my needs and very useful in general. I was trying to implement it and had a few questions:
1) Is there a way to work around the need for all the separate linear models using the same dataset? My problem is that this unnecessarily reduces my sample size for some paths. I can use some data points “upstream” and not ‘downstream” if that makes sense.
2) Should I use nlme or lme4? I’ve tried both and they both give errors (“invalid formula for groups” for nlme and “lmerTest did not return p-values. Consider using functions in the nlme package.” for lme4
Thanks again
Amos
Hi Amos (hopefully not the AMOS program!!), Happy to assist.
(1) I’m not sure I follow. The basis of piecewise SEM is the listed of structured equations, which can be estimated locally, fit to the same dataset. Do you mean that you have hierarchical data such that values of one variable are repeated over unique values of another?
(2) I recommend nlme because it has fewer problems with convergence, and therefore greater likelihood of returning P-values with which to construct the d-sep test. Sounds like you have a problem specifying your random structure. Drop me a line and we can get it sorted.
Cheers,
Jon
Hi Jon,
I’m using your piecewiseSEM package (it’s great…thanks!). I have a question about interpreting path coefficients when there are different types of glm links being used (binomial, poisson). In your example in the vignette:
(https://cran.r-project.org/web/packages/piecewiseSEM/vignettes/piecewiseSEM.html)
there are both binomial and Gaussian families used. When you do sem.coefs(shipley2009.modlist, shipley2009, standardize = “scale”) it gives the warning
(## Warning in FUN(X[[i]], …): Reponse ‘ Live ‘ is not modeled to a gaussian
## distribution: keeping response on original scale.
I’m a little unclear what this warning means–is it still scaling all models (Gaussian and binomial)? I just want to check that I can compare the path coefficients from this scaled output. Thanks!
-Ellen
Hi Ellen,
Thanks for the kind words! The warning is meant to imply that centering and scaling the response would no longer make it binomial- or Poisson-distributed. (i.e., it has gone from 0-1 to something altogether different, or whatever). The d-sep model would then kick back an error saying the variable is not binomially, etc. distributed. There are two ways around this: understanding that the standardized predictors are in units of standard deviations of the mean, so that a 10^1 sd change in predictor X results in a 1 unit change in the predictor (if you were modeling a Poisson variable with a log-link) OR transform the response so that it can be centered and scaled. Make sense? Hope this helps!
Cheers,
Jon
Thanks, Jon. That helps a lot!
Best,
Ellen
Hi Jon,
I ran into a couple more questions. Can you use semPlot (or is there something equivalent) with piecewiseSEM? I tried it but it didn’t seem to work. Also, “lmer” models (package lme4) give a warning for sem.fit (‘lmerTest did not return p-values. Consider using functions in the nlme package’). Am I restricted to using “lme” models (package nlme)?
Thanks for your help,
Ellen
Hi Ellen,
I have tried to implement semPlot with piecewiseSEM, but it would be difficult. I should contact the package author to see if they would be interested in helping to implement it.
As for lmerTest, it has convergence errors more often than not, in my experience. In that case, it doesn’t approximate the ddf and therefore doesn’t return a p-value, which is essentially for the tests of directed separation. In this case, I recommend using nlme since it (more) reliably returns p-values. If you have non-normal variables, you may consider log10-transforming count data. Another option is to use glmmPQL from the MASS package which allows for non-normal data but fits using lme.
Let me know if you continue to run into problems and we can try to work something out.
Cheers,
Jon
Hello Jon,
I had used piecewiseSEM earlier this year with a dataset containing binomial and NB-distributed response variables and a random effect. I had used glmer and glmer.nb and got some warnings, but it worked. I just re-installed piecewiseSEM today and now with the same data and model code I am getting this error message:
> modList = list(
…. )
Warning messages:
1: Some predictor variables are on very different scales: consider rescaling
2: In checkConv(attr(opt, “derivs”), opt$par, ctrl = control$checkConv, :
Model failed to converge with max|grad| = 0.00168764 (tol = 0.001, component 2)
3: In checkConv(attr(opt, “derivs”), opt$par, ctrl = control$checkConv, :
Model is nearly unidentifiable: very large eigenvalue
– Rescale variables?;Model is nearly unidentifiable: large eigenvalue ratio
– Rescale variables?
4: In theta.ml(Y, mu, sum(w), w, limit = control$maxit, trace = control$trace > :
iteration limit reached
5: In sqrt(1/i) : NaNs produced
> sem.fit(modList, df1)
Error in matrix(rep(0, dim(amat)[1]), nrow = 1, dimnames = list(responses)) :
length of ‘dimnames’ [1] not equal to array extent
Is glmer.nb no longer supported?
Thanks!
Katy
Hi Katy, Fixed in the latest version on GitHub (1.0.1, 2015-12-07). Just noting here for the record! Cheers, Jon
Hi Jon,
Many thanks for piecewise SEM. That’s a great ecological tool! I have been working using it. However, when I try to run it with my data I get some errors.
When I try to use the “sem.fit()” function I am getting this error message:
#Error in topOrder(amat) : The graph is not acyclic!
In addition: Warning message:
In get.dag(formula.list) : The graph contains directed cycles!#
Besides that, when I have tried to explore individual model fits using the sem.model.fits() I’m getting this error message:
#Error in terms.formula(formula, data = data) :
‘data’ argument is of the wrong type
Why do you think it is going on?
Many thanks in advance,
Hi Pablo, This warning means your SEM is recursive. In other words, you have feedback loops, such as A -> B -> C -> A. Unfortunately the framework at the moment cannot handle such paths. You will have to reconsider the topology of your network — sorry! Cheers, Jon
Dear Jon,
I’m trying to use your package to test a SEM model on my data and I got the following message : “Error: Model is recursive. Remove feedback loops!”.
I don’t thing there is any loop in my model :
my.mod4<-psem(
lm(LightF~RaoQ+sqrt(CWM),my.data4),
lm(LightF2~RaoQ+sqrt(CWM),my.data4),
lm(Haut~LightF+LightF2+Stock,my.data4),
lm(logBMS~LightF+LightF2+Stock,my.data4),
lm(RaoQ~Stock+Scarcity,my.data4),
lm(CWM~Stock+Scarcity,my.data4),
Haut%~~%logBMS,
LightF%~~%LightF2,
RaoQ%~~%CWM
)
Do you have any clue to help me ?
Many thanks !!
F.Dommanget
Yes this might be a bug…please file an issue on Github! Thanks, Jon
Thanks for this Jon!
I have considered SEM for a while now, but never really made it work. This is helping a lot and I managed to apply your tutorial to my data (yes!) – so first of all thank you very much 🙂
However, I have absolutely no formal training in statistics (or ecology), but ended up doing my PhD about soil microbial communities… Now I know at least some things 😉
Making SEM work on my data now puts me in front of several questions – these might well be very basic, but we have very few people around who really work with statistics, or know their way around ecological modeling or else… So should I better shoot you an email (so I don’t bore the rest of your readers to death? 😉
Thanks in advance,
have a great day!
Hi Kristin, Absolutely, drop me a line and we can work through it! Cheers, Jon
Hi Jon,
I saw that you are working on a ‘helper function to get scaled model for sem.coefs’ in GitHub. What does this do? Does it help get standardized coefficients from glmer models? Thanks!
Ellen
Hi Ellen, This function was already included with
sem.coefsand the argumentstandardize = "scale", but people were having issues with transformed and offset variables in the model formula. That lead me to create the helper function to break apart the formula, transform the variables, scale the data appropriately, and refit the model, since it was getting too unwieldy to do in the original function. Cheers, JonI see, thanks Jon! Best,
Ellen
Great package, thank you. I’m having a problem where I can fit a model, but I can’t get sem.coefs or sem.model.fits to work.
The following works fine:
Model2.modlist = list(
lm(Hydroperiod~LandUse+Temperature, data =frog.data),
glm(Frog.count~Hydroperiod, data =frog.data, family=”poisson”)
)
Model2.result=sem.fit(Model2.modlist, frog.data)
But when I do the following:
sem.coefs(Model2.result, frog.data)
I get this error message: Error in order(response, p.value) : object ‘response’ not found
I’ve tried changing my lm to glm and changing my poisson glm to glm.nb, but get the same error message. Am I using an supported model? Thank you for any help. Barney
Hi Barney, Thanks for getting in touch. You *almost* had it!
sem.coefsaccepts the model list, not the summary output. So the revised code you are looking for is:sem.coefs(Model2.modlist, frog.data)Which should produce the coefficient table you seek. Best of luck, Jon
Oh, so close. Thanks for fixing that for me.
🙂
Hi Jon,
It is me again, sorry for bothering you. But, I am kind of stuck in some issues with SEM. First of all thanks for a great package and the nice tutorials, I have really enjoyed them.
Here is my problem:
I have data from a mesocosm experiment, in which I measured a bunch of stuff (chemical, biological, and physical parameters), it is a fully factorial experiment with 5 experimental blocks, so I should use random effects, and that is why piecewise SEM is perfect for me. I want to estimate the magnitude of the direct and indirect effects of my treatments (fish population x density x infection ) at multiple levels (e.g. mesograzers and pelagic algae).
So my questions are:
1. Can I use my experimental treatments (main effects and their interactions) as exogenous variables in a piecewise SEM to estimate their direct and indirect effects?. if so, there will be 7 exogenous variables that are uncorrelated. Which bring me to the next question.
How many endogenous variables (response variables) can I use in the model? because if I follow the d-rule, I will be allowed to use no more than two variables. I have 40 samples, 5 x 8 treatments:
A => X1
B => X1
C=> X1
A*B=> X1
A*C=> X1
B*C=> X1
A*B*C=> X1
X1 => X2
Writing Shipley’s book 2000, I found a chapter about multigroup SEM, What I understood is that multigroup SEM tests the differences in the covariance of a network of interactions, and test the effects of some treatments. But since, I want to estimate the direct and indirect effect, I am not sure if I should use it. What would think?
Thanks so much for your help,
Best regards,
Jaime
Hi Jaime, Three-factor experiments are troubling to fit into an SEM framework. I am struggling with it myself currently. Why don’t you send me an email and we can discuss the specifics of your design, and what approach might be best. Cheers, Jon
Hi Jon,
I have started to use your piecewiseSEM package which seems to be a very good approach for my purposes. However I am getting this warning message:
Warning message:
In FUN(X[[i]], …) :
Some d-sep tests are non-symmetrical. The most conservative P-value has been returned. Stay tuned for future developments…
Strangely I did not get this warning message before….
Thanks,
Theresa
Hi Theresa, Yes this is an issue when there are intermediate endogenous variables that are modeled to a non-normal distribution. The transformation via the link function (e.g., log(x) for Poisson) means that the formula
y ~ xdoes not return the same P-value asx ~ ywhich makes a difference in constructing the d-sep tests. At the moment the code returns the lower of the two P-values for the two formulas. But we’re working on some conceptual updates that may fix this error. Stay tuned… JonHi Jon,
Thank you for this detailed and clear explanation of piecewiseSEM and for the examples that you have provided. Super helpful! I have been applying these methods for the first time to a project (scary!), and I was hoping that you could provide feedback for whether this analysis makes sense and is applied correctly? Here it goes. I want to evaluate the contribution of road and gas wells (as distance from leks) on background noise (measured at the lek) and consequently see if they are linked to declines of sage-grouse at leks (N=22). I’ve provided the code and R results below. My interpretation of these results is that both well distance and road distance “cause” noise, but that well distance is 2x as important as road distance, and that noise leads to (causes? can I say that?) declines. Is that an appropriate interpretation? Also, I do have another covariate (X3, if you will), percent decline in sagebrush, that is not related to noise but could be linked to declines and I’m not sure I understand how to include this path. Any guidance here would be very helpful. Thanks so much, Holly
####################################################################
The model list:
mydf.modlist = list(
lme(Median_L50 ~ RoadDistM + WellDistM, random = ~1|SiteNum, na.action = na.omit, data = mydf),
lme(Negbin_tre ~ Median_L50, random = ~1|SiteNum, na.action = na.omit, data = mydf)
)
####################################################################
R Results (the model passed the Fisher’s C test)
> #Extract path coefficients
> sem.coefs(mydf.modlist, mydf, standardize = “scale”)
response predictor estimate std.error p.value
1 Median_L50 WellDistM -0.6408378 0.1489238 0.0004 ***
2 Median_L50 RoadDistM -0.2936578 0.1489238 0.0634
3 Negbin_tre Median_L50 -0.6276897 0.1740698 0.0018 **
Hi Holly,
Thanks for getting in touch. This seems like a great application of SEM because you have indirect, cascading effects (distance & wells -> noise -> lek abundance).
Your interpretation is reasonable: not only is the distance of wells from the lek 2x more important than road distance in reducing noise (based on those standardized coefficients), but it is actually the only ‘significant’ contributor (P < 0.001 vs P = 0.06).
You can further calculate the indirect effect by multiplying the standardized coefficients: -0.64 * -0.63 = 0.40. Note that the sign changes, implying that increasing distance from wells indirectly increases lek abundance by directly reducing noise.
Adding another covariate is possible but keep in mind that the `sem.fit` function will then test for other associations between this variable (X3) and unlinked variables in the model. So ,for instance, if you added it to your first model, the goodness-of-fit tests would include an additional independence claim between `Negbin_tre ~ X3`. This could be good or bad, depending on whether this relationship is significant and changes the fit of your model.
Give an email if you want to discuss further. (I did send you a reply and never heard back, but happy to have the exchange in public in case others can benefit from this conversation!)
Cheers,
Jon
Hi Jon,
thanks so much for this summary. It is really helpful to clarify some points. However, it raises me other doubts that are probably more related with the words that the different authors uses than with the statistics.
Shipley (2002) states :”Two different ways of testing causal models will be presented in this book. The most common method is called structural equations modelling
(SEM) and is based on maximum likelihood techniques. (…) These drawbacks led me to develop an alternative set of methods that can be used for small sample sizes, non-normally distributed data or non-linear functional relationships (Shipley 2000) that I will call these d-sep tests”.
From here, it seems that SEM and d-sep tests are just two methodologies to test causal models. Howeve, from Shipley (2013) and you I interpret that SEM is an statisitcal technique for multivariate analyses that can be evaluated used d-sep test (or AIC). Even more, when you go to MPlus, the concept of “piecewise SEM” is not used at any moment even when includes non-normal distributed or latent variables. Can you shed light on this? It is a little confusing
Secondly, regarding the evaluating methods, are both d-sep and AIC comparison independent procedures? It seems from Shipley that to compute AIC one needs to perform d-sep procedure. But this seems weird to me. Can I use simply the AIC model comparison to select by best “path model”? or since I need the LogLikelihood for computing AIC the only way is to use d-sep test?
Thanks,
Isabel
Hi Isabel,
Certainly! It may be more helpful to think of the first method in terms of “global estimation,” where relationships for the entire causal network are solved simultaneously (this is what is referred to by Shipley as the “common method”). The d-sep tests are a form of “local estimation” where each path is solved independently from the others. It amounts to simply estimating each (multiple) linear regression by itself.
Because each equation is solved individually, each response can be modeled to its own (potentially non-normal) distribution and set of assumptions. This makes the piecewise technique a lot more flexible, as Shipley has argued.
(Latent variables are tricky and are not yet implemented in a piecewise framework.)
As for your second question, the d-sep tests — evaluating the “independence claims” or missing paths in your diagram — provide significance statistics (P-values) that are used to construct the AIC value. So yes, Shipley is correct that, in computing AIC, one must first conduct the d-sep tests.
The d-sep tests that produce the Fisher’s C statistic, which is used to infer goodness-of-fit, and the AIC value, which is used to make model comparisons, are two sides of the same coin. One evaluates the independent fit of the model, i.e., does it reproduce the data well, or are there missing relationships that are important given the data? The other is used to compare different topologies. One can use AIC to infer a more likely topology but still have a poor-fitting model, in the same way you can select the most parsimonious regression from a candidate set but it still has low explanatory power (e.g., low R^2). Make sense?
Hope this helps!
Cheers,
Jon
Hi again Jon,
and thanks for your clarification. It is putting order in my head
Anyway, regarding my second question, Shipley uses the p-value to compute C and using C he proposed to calculate AIC using the formula you wrote above. Original definition of AIC from Akaike (1987) is AIC = -2logL + 2*r where r is the number of free parameters, right? This makes ask me some questions:
1. C is just the “gobbledygook” in brackets or also the -2ln? if the latter is true, AIC = C+2K, right?
2. Is there no other way to estimate the likelihood of a Piecewise SEM without using C, and the d-sep test? I mean, several programs like MPlus gives a likelihood and AIC value but I found no reference to Shipley’s d-test
3. And, overall, how your PiecewiseSEM package calculates the LogLikelihood of a path and so the AIC? Using d-sep and C, I guess, am I right?
Bests,
Isabel
Hi Isabel, 1. the C replaces the log-likelihood component, so everything to the right of the 2*r; 2. The AIC given by those programs is for global estimation, i.e., the whole vcov matrix is estimated using ML so there is a more straightforward formulation of AIC. As it stands, Fisher’s C is the only way to compute an AIC score for SEMs fit using local estimation; 3. The likelihood is captured by Fisher’s C (see Shipley’s 2013 paper in Ecology). The likelihood df are pulled directly from the models. — Let me know if this makes sense and if you need any more clarification! Cheers, Jon
Hi again Jon,
certainly, now I am a little more confused. In your reply above, are you saying that some programs estimate the whole vcov matrix for Piecewise SEM using ML?
From this tutorial I understood that this is not possible. Above, in this page I can read that for Piecewise SEM we are “estimating a separate variance-covariance matrix for each piecewise model” (for each single equation of the piecewise SEM, right?). And also, that we are not “reproducing the entire variance-covariance matrix among all variables” as we do in traditional SEM.
So, and sorry for the direct question, is it possible or not to estimate a whole vcov matrix for Piecewise SEM?
Probably my misunderstanding is because I do not understand very well the difference between local and global estimation, can you recommend me any lecture?
Thanks for your patience! I promise no more questions 😉
Hi Jon,
Thanks for your work on this great R package. I have a question about effect sizes for pathways in glmer models. One of the strengths of SEM is visually showing the strengths (effect size) of explanatory variables via the size of the arrows in the SEM figure with boxes and arrows. This is great when all response variables have Gaussian distributions because you can compare the strengths of pathways across the entire SEM via standardized coefficients. Is there a way to do this for pathways in generalized linear mixed-effects models (glmer)? My SEM has three response (endogenous) variables – one is binomial and the other two have Poisson distributions. Thus I have three glmer models within the SEM. I have random effects too, to account for the hierarchical design (plots nested in sites) and I’m using the glmer function in lme4. I can’t center and scale the responses. Standardizing the predictors doesn’t quite get me the solution either, I think. How do you recommend I depict the arrows and coefficients in the SEM plot? What is most meaningful and easiest for the reader to understand? I will have the ANOVA table of all the fixed effects – coefficients of non-standardized predictors, standard error and p-values (from sem.coefs). But what/how can I show these best in the SEM figure? One more complication, one of the predictor variables is a binomial variable (the response variable with the binomial distribution, presence/absence). I assume I can’t standardize this as the predictor variable.
Hi Nick, Yes you have hit the nail on the head when it comes to local estimation. We are working on this as we speak, it may be simpler than you think. If you like, you can download the development version of the package:
library(devtools); install_github("jslefche/piecewiseSEM@2.0")where we have implemented a working version of a solution. However, BE WARNED! This will overwrite your current version of piecewiseSEM (1.4) and has a very different (but more familiar) syntax. It may be that our solution does not stand up to scrutiny so I would take any estimates with a heaping chunk of salt until we are confident we have a solution — we will release the package to CRAN when that happens! Cheers, JonHi Jon, thanks for a great package! Can you provide a working example for using sem.fit with glmmadmb within model list? I tried to change glmer function to glmmadmb in the “shipley2009.reduced” data but sem.fit gives this error: unused argument (control = control). If I change “sem.missing.paths” function that sem.fit uses (use admb.opts = control, instead of control = control since it seems that glmmadmb uses this argument in the model formula) I get another error saying that all grouping variables in random effects must be factors (but they are!). So, I got stuck a bit..
Hi Vesna, Sorry I see you also emailed me and filed a bug on Github, but I just returned from a whirlwind of travel. This may have to do with the bug someone recently uncovered when the dataset is named ‘control’. I am working on a development version of the package and hope to have support for
glmmadmbsoon. Is the analysis urgent? If so drop me a line. Cheers, JonThanks Jon for your great post, I am using piecewise SEM because a have a relatively small data set but I am including some two-way interactions, and I wonder why the scaled estimate for one of the interactions is greater than one.
Here is the model and some results:
chla_SEM = list(
ChlaMaxS = lm(ChlaMaxS ~ SSD*period+SST*period+SPMS*period, data = pchla),
SST = lm(SST ~ PDD, data = pchla),
Q = lm(Q ~ PDD, data = pchla),
SSD = lm(SSD ~ Q, data = pchla),
SPM = lm(SPMS ~ Q, data = pchla)
)
sem.coefs(chla_SEM, pchla, standardize = “scale”)
response predictor estimate std.error p.value
1 ChlaMaxS SSD:periodafter 2.4939955 0.705944938 0.0026 **
2 ChlaMaxS SPMS 0.4187186 0.128841642 0.0047 **
3 ChlaMaxS periodafter:SPMS -0.5586233 0.272587009 0.0562
4 ChlaMaxS SSD -0.1158602 0.095550453 0.2419
5 ChlaMaxS SST 0.1109951 0.092051462 0.2444
6 ChlaMaxS periodafter 0.4089875 0.428126531 0.3528
7 ChlaMaxS periodafter:SST 0.2041288 0.597129420 0.7367
…
do I have to eliminate the nonsignificative interactions using AIC for model comparison?
Hi Leonardo, The units of standardized coefficients are in standard deviations of the mean. Thus, assuming the errors on the estimates are very small, it is possible to have a standardized coefficient that is very large, i.e., larger than 1. As for the non-significant interactions, that is up to you: you obviously included them in the model because you thought they were mechanistically important. I would caution against removing them for statistical reasons (e.g., non-significant P-value) since this goes against the core philosophies of SEM. If you chose to proceed with AIC comparisons, recall that you must include all variables in nested models, even if they have no links, using the
add.vars =argument insem.fit. Good luck! JonHi Jon
Thanks for PiecewiseSEM! I had ruled using SEM out, given the nature of my data,until someone mentioned piecewiseSEM.
I’m just struggling a bit as I have 2 categorical variables, one with 2 levels and another with 3 levels, and I need to know the effect of the interactions between the 2. I’m looking at the topdown indirect/direct effects of the interactions between Rotation (x3) and Treatment (x 2) on Yield and how the relationships change for each Rotation x Treatment interaction. (I hope it makes sense!)
The models run, but I’m struggling to interpret the output: (see below)
stress_SEM1 = list(
#Soil
lme(FBRatio ~ Rotation * Treatment, random = ~1|Block/Rotation, na.action = na.omit,
data = SEMmatrix),
lme(SoilC ~ FBRatio, random = ~1|Block/Rotation, na.action = na.omit,
data = SEMmatrix),
#Resilience
lme(RootLenght ~ Rotation, random = ~1|Block/Rotation, na.action = na.omit,
data = SEMmatrix),
lme(Moisture ~ Rotation * Treatment + RootLenght, random = ~1|Block/Rotation, na.action =
na.omit, data = SEMmatrix),
lme(CT ~ Moisture, random = ~1|Block/Rotation, na.action = na.omit,
data = SEMmatrix),
#Yield
lme(Yield ~ Rotation * Treatment + SoilC + CT, random = ~1|Block/Rotation, na.action =
na.omit, data = SEMmatrix))
sem.coefs(stress_SEM1,SEMmatrix,standardize = “scale”)
response predictor estimate std.error p.value
1 FBRatio Rotation[T.Simple]:Treatment[T.Stress] -1.40647572 0.90999658 0.1608
2 FBRatio Rotation[T.Simple] 0.66192267 0.64346476 0.3433
3 FBRatio Rotation[T.Moderate] 0.48885799 0.69708956 0.5094
4 FBRatio Rotation[T.Moderate]:Treatment[T.Stress] -0.43590264 0.94867314 0.6581
5 FBRatio Treatment[T.Stress] -0.29544317 0.64346475 0.6583
……..
So, sem.coefs() does not show the output of all the interactions for the 2 categorical variables. Can you guid eme on how to extract all the coefficients?
Also, I understand I can calculate the indirect effects by multiplying the standardised coefficients. Does having interactions in the model change this?
And finally, how can I interpret the arrows on the sem.plot() function?
Any help in the right direction will be really appreciated!
Many thanks!
Erika
Hi Erika, Send me an email. I am rewriting the package from the ground up and it seems that your issue with interactions might be solved by that, but probably easier to guide you through via email. Cheers, Jon
Hi Jon, thanks for the nice work. I have been using piecewise SEM in manuscript I am near to submit.
I write here because I have a quick question: is it possible to fix a sign of a relationship? For instance, I know that A and B are negative correlated, but when I run the model (which has several paths) the relationship between A and B becomes positive. Ecologically it is implausible to have a positive relationship between A and B. So, that is why I would like to make A and B with a fixed negative relationship.
Hope I got my point clear.
Best,
Francisco
Hi Francisco, Its possible to fix a relationship to zero but not the sign. The data are telling you that, when controlling for other covariates, the relationship is positive. Unfortunately, this issue lies with your data and not the technique. I recommend going back to the drawing board with your model structure and doing a bit of data exploration as well to get to the bottom of it! Cheers, Jon
Hi Jon,
Again, many thanks for this very nice work!
I am using the piecewiseSEM approach in my studies, and in a ms review, the referee suggested that the significance of the paths should be tested by bootstrapping and not with maximum likelihood estimators. Can I do this using piecewiseSEM?
Thanks for your support,
All the best,
Pablo
Hi Jon,
Thanks for your piecewiseSEM package, I am using it right now. However, there seem to be some problems about sem.coefs() function. As we I choose standardized coefficients(by setting standardize = “scale”), all the interaction terms are gone. However, when I do not choose standardized, I could see the output include interaction terms. Could you help to guide me how to extract the standardized coefficients of interaction terms? Please see some code and results below.
Thanks very much.
######## when chose standardized coefficients
sem.prelist <- list(
glmer(prtick~prmite+NPC1+prmite:NPC1+(1|SITE),data=data1,family="binomial"),
glmer(prmite~prtick+NPC1+prtick:NPC1+(1|SITE),data=data1,family="binomial")
)
sem.fit(sem.prelist,data1)
coef.table=sem.coefs(sem.prelist,data1,standardize = "scale")
coef.table
response predictor estimate std.error p.value
1 prtick NPC1 -0.4281677 0.5093557 0.4006
2 prtick prmite 0.2196158 0.2962617 0.4585
3 prmite NPC1 0.1924008 0.1623395 0.2359
4 prmite prtick 0.2916433 0.2819740 0.3010
######## when do not chose standardized coefficients
sem.prelist <- list(
glmer(prtick~prmite+NPC1+prmite:NPC1+(1|SITE),data=data1,family="binomial"),
glmer(prmite~prtick+NPC1+prtick:NPC1+(1|SITE),data=data1,family="binomial")
)
sem.fit(sem.prelist,data1)
coef.table=sem.coefs(sem.prelist,data1)
coef.table
response predictor estimate std.error p.value
1 prtick prmite:NPC1 -0.89447284 0.3129724 0.0043 **
2 prtick NPC1 -0.17663704 0.5274744 0.7377
3 prtick prmite -0.08410281 0.3445041 0.8071
4 prmite prtick:NPC1 -0.91916967 0.3138918 0.0034 **
5 prmite NPC1 0.33134250 0.1659660 0.0459 *
6 prmite prtick -0.05146762 0.3361003 0.8783
Dear Jon,
Just have another problem during the use of piecewiseSEM. The modeling building is not an issue I think, but I can not get the AIC value and Fish’s C statistics. When using “sem.fit” function, I got the error “Error: All endogenous variables are conditionally dependent.
Test of directed separation not possible!” See the code below, could you help try to specify where I did wrong? thanks very much.
##########
prtick & prmite are two kinds of parasites, and here the model trying to detect their competition and whether the competition is mediated by the environmental factors (NPC1,NPC2, they are PCA scores). prmite & prtick are the presence of parasite (0/1, binary). As my data involve in multiple sites, so I included site as the random factor. I add the interaction term because in the previous analysis we found that one kind of parasite was negatively correlated with the interaction between environments and the other parasite.
##########
sem.prelist <- list(
glmer(prtick~prmite*NPC1+prmite*NPC2+(1|SITE),data=data1,family="binomial"),
glmer(prmite~prtick*NPC1+prtick*NPC2+(1|SITE),data=data1,family="binomial")
)
sem.fit(sem.prelist,data1)
Error: All endogenous variables are conditionally dependent.
Test of directed separation not possible!
I also hit an email to you, hope you could provide some advice.
Thank you very much.
Best wishes
Qiang
Hi Qiang,
Thanks for reaching out!
This error means you have no missing paths with which to construct goodness-of-fit tests. In other words, you have a fully saturated or just identified model. You could attempt to remove paths, but I recommend looking at the R^2 values of the individual models to gauge fit qualitatively.
As for your second question, see the dev version of piecewiseSEM on Github:
library(devtools)
install_github(“jslefche/piecewiseSEM@2.0”)
library(piecewiseSEM) # should have welcome message for new version
# then see
?psem
?coefs
# and possibly
vignette(“piecewiseSEM”) # Section 3
Hope this helps!
Cheers,
Jon
Dear Dr Lefcheck
Thank you for developing the great package. I have waited for a package of SEM that can handle quantile regressions! While I analyze my data using piecewiseSEM now, I have noticed a small variance in the AIC output of sem.fit() when quantile regression is used in the model. Rerunning of sem.fit() on the same model shows a slightly different estimate. Here is an example using data(shiplay2013). The version of my R is 3.3.3 and piecewiseSEM 1.2.1. In cases of lm and glm, this seems not to occur. It is much appreciated if you would tell me why this occurs when quantile regression was used. Thank you in advance.
Best regards
Kenji
data(shipley2013)
library(quantreg)
shipley2013.modlist = list(
rq(x2~x1, tau=0.9, data = shipley2013),
rq(x3~x2, tau=0.9, data = shipley2013),
rq(x4~x2, tau=0.9, data = shipley2013),
rq(x5~x3+x4, tau=0.9, data = shipley2013)
)
#repeating the sem.fit() on the same model
aic<-list()
for(i in 1:10){
aic[[i]]<-sem.fit(shipley2013.modlist, shipley2013)$AIC
}
aic
Because the P-values for `rq` are obtained by bootstrapping they are slightly different each time. Hence the discrepancy!
Hi Jon,
Congratulations for the piecewiseSEM package, it is really helpful. I have been using the first version and now I am with the 2.0. I started with this newer version because I got the error message :”Error: All endogenous variables are conditionally dependent.
Test of directed separation not possible”. I read that someone else had that problem and you suggested to use the new version.
I tried but could not make it run. I think I was successful when using psem function but when I tried to use “coefs” , “dsep” and “summary.psem” I get error messages (e.g. Error in FUN(newX[, i], …) : invalid ‘type’ (character) of argument for “coefs and “summary.psem”; and “data frame with 0 columns and 0 rows” when I try dsep).
This is my code:
sem <- psem(
lme(FRP~CO2+AirTempMean+MoistMean+AirTempMean:CO2, random=~1|Ring.ID,YearDATA),
lme(MoistMean~AirTempMean*CO2,random=~1|Ring.ID,YearDATA)
)
coefs(sem)#Error
dSep(sem)#Error
summary.psem(sem)#Error
CO2 is a factor with two levels, AirTemp and Moist are continuous and Ring is the grouping factor.
I could not find many documentation for these problems so I am directly asking to you. Maybe you could help to find what is going on.
Best regards,
Juan
Hm can you contact me by email directly? Thanks!
Hi Jon,
I have the same problem as Juan.
This is my code:
Mesocosm_pSEM_randomList = psem(
Flore20_07_model=glmer(Flore20_07 ~ Traitement*EPPO+Count +(1|Num_mesocosm),data=data_test, family=poisson),
Seedbank = lme(log(Banque+1) ~ Traitement*EPPO + Flore20_07 ,random=~1|Num_mesocosm, data = data_test)
)
When I do:
summary(Mesocosm_pSEM_randomList, data_test)
coefs(Mesocosm_pSEM_randomList, data_test)
I get the following error message:
Error in FUN(newX[, i], …) : invalid ‘type’ (character) of argument
Flore20_07, Count and Banque are continuous variables and Traitement, EPPO and NUM_mesocosm are factors.
Best regards,
Benjamin
Hi Jon,
First of all, thank you very much for all the work you put into your piecewiseSEM package. It’s great and it opens up a lot of possibilities!
I’ve got one question regarding it’s implementation. From what I’ve read, with classical ML methods (i.e. lavaan), centering variables is recommended, but standardizing them is not. However, when modelling individual GLMs, statisticians recommend centering and standardizing predictors in order to improve model performance and interpretability (e.g. Schielzeth, 2010; Harrison et al 2017). What’s the recommended procedure with piecewise SEM?
Once again, thank you very much!
Cheers,
David
It depends on what the centering and scaling is meant to accomplish. The standardized coefficients reported by lavaan and piecewiseSEM reflect centered and scaled data (try it and see!), but centering and scaling may also be useful to reduce issues with multicollinearity.
Centering and scaling, however, can defeat the purpose of using GLM if the data that are modeled using a non-Gaussian distribution (since centering and scaling means that the response no longer adheres to the properties of that distribution).
Hope this helps!
Yes, it does. Thank you very much for the quick reply! It’s very kind of you!
Cheers,
David
Dear Jon,
I’m building piecewiseSEMs with random effects, correlation structure and response variables with different distributions. I used glmmPQL to define the binomial model, but when I include it I receive the error message,
“Error in sem.model.fits(mA) :
(Pseudo-)R^2s are not yet supported for some model classes!”
Any advice on how to get some information for the individual model fit for that binomial model? I do get pseudo R2s when I just run the lme models. Does piecewiseSEM support any other packages that can handle random effects, correlation structure and binomial responses?
Thanks,
Annise
Dear Jon,
I’m building piecewiseSEMs with random effects, correlation structure and response variables with different distributions. I used glmmPQL to define the binomial model, but when I include it I receive the error message,
“Error in sem.model.fits(mA) :
(Pseudo-)R^2s are not yet supported for some model classes!”
Any advice on how to get some information for the individual model fit for that binomial model? I do get pseudo R2s when I just run the lme models. Does piecewiseSEM support any other packages that can handle random effects, correlation structure and binomial responses?
Thanks,
Annise
Hi Annise, Check out the function
rsquaredin the development version of piecewiseSEM. You can find it here. It should have support for quasi-distributions and many more based on some newer work! Cheers, JonHi Jon
This package is just extraordinary. It is very simple to connect direct and inderect effects and test if the causal model will get accepted or not.
I already used the piecewiseSEM package to fit a glmer with a random factor and several fixed factors, it worked perfectly. Now I’m trying to use a more simple linear mixed effect model (nlme package) with again one random effect and some inderect effects on the predictors of the first global model. Everything is working fine, I get the partial regression coefficents from the nice sem.coefs(piecewiseSEM) function, also the R2, but I do not get a p-value (it is always = 0), although the goodnes of fit test gives me a fisher C stats. I tried to increase and also decrease the model list complexity but it did not help. Do you have any solution?
sem<-list( #basic model predicting decomposition by decomposer soil fauna
decomposition = lme(response~ SR_tot_z + Abun_tot_z + FDis_z + habitat + type , random = ~1 | ID),
#Predicting Abun_tot
Abun_tot = lme(Abun_tot_z ~ overwarming_z + bareground_z, random = ~1 | ID),
#Predicting SR_tot
SR_tot = lme(SR_tot_z ~ plant_SR + bareground_z, random = ~1 | ID))
$Fisher.C
fisher.c df p.value
74.62 24 0
$AIC
AIC AICc K n
112.62 118.422 19 151
Class Family Link n Marginal Conditional
decomposition lme gaussian identity 151 0.3836700 0.7181827
Abun_tot lme gaussian identity 151 0.1825187 0.2707284
SR_tot lme gaussian identity 151 0.1292219 0.4531946
Thank you very much!
Kind regards,
Simon
Hi Simon, A low P-value on your model suggests that there are missing paths present that are highly significant, which is drawing down your goodness-of-fit statistic (Fisher’s C). Try running
sem.missing.paths(sem)to identify the offensive paths. Whether then you choose to add them to your model to improve the fit is a philosophical question: are you in a more exploratory or confirmatory mode of SEM? Cheers, JonThank you very much Jon!
We run the analysis with different model set and included the missing paths and have now a reasonable Fisher’s C statistics of 0.98.
Hi, Jon!
First of all, thank you very much for the piecewise package!
I am having trouble to understand when and how should I scale my variables. We are trying to use PiecewiseSEM because we have a lot of non normal dependent variables (some are beta-distribuited, some are lognormal). One of our goals is to state which independent variable (between a set possible variables) is more important to determine a dependent one. To do so, we expected to look at the standardized coefficients of the full model (as we normally interpret the selected models in the model selection approach) . Our first doubt was about how should we standardized our once dependent variable in those part of the model they are independent. While looking for the answer we found that many times, when variables are not normally distributed, the package does not standardizes it. So, our current doubts are: if we inform the function (scale = T), how should we interpret the coefficients in a model with a lot of non-normal dependent variables? Is it possible to compare coefficients between independent variables in models with non-normal distribution? When the variable is “acting” as independent, does it get scaled in the function but not when it is the dependent? Should we be trying to figure out the distribution of the scaled dependent variable and use it as our primary variable all along or should we include our variable as we have it (and inform the distribution that we have already decided) and let the function scales it?
An example:
The model:
C(beta distribuited) ~ B + A
E(log-normal distributed) ~ C + D.
We wish to determine whether B or A is more important and whether C or D is more important. Should we inform just like this or should we scale first, evaluate the distribution and then construct the model:
C_scaled<- scale(C)
The model:
C_scaled(to be discovered distribution )<- scale(B) + scale(A)
E_scaled(to be discovered distribution) ~ C_scaled + scale (D).
Is it clear? If the first option is correct, then can we compare coefficients?
Hi Gabriela, Yes this is a well-known issue for piecewise SEM. The technique is flexible in that many different models forms can be fit, but scaled coefficients are unavailable for non-normally distributed responses. We are working on implementing them for binomial GLMs, but that requires some theoretical advances and is proving more time-consuming than anticipated. The development version of the package on Github will return standardized coefficients in that particular case, otherwise, I would ignore the values for anything other than Gaussian models (they are only x-standardized). Sorry about that! Cheers, Jon
Hi Jon! Thank you for your quick response! No need to be sorry! I get it now! Now I have another question: there is one variable that can be measured in different ways and conceptually we cannot choose between them, so we wish to choose between them analytically. Normally we would use the model selection approach and choose the measure included in the model with the smaller AIC (in a set of models that only differ in the used measure). From what I have learned about SEM/piecewiseSEM so far, it is only possible to compare nested models and them it would not be possible to create two models (one with the first option and another with te second option) and compare their coefficients or AIC, right? Do you have any suggestions on how could we choose our measure?
Thank you again!! Gabriela
Hi Jon! I thought I understood the thing about the scale argument, but now I’m not sure anymore. When we analyze multiple regression (doesn’t matter if they are normally distributed), we usually scale all independent variables and then we create the model using the scaled variables. Why it is not possible to do the same in a piecewiseSEM model (i.e. scaling all variables – including “dependent” variables – and then create the full model with the scaled variables)? Does the scale argument means something different than setting the same variation scale for all variables?
Thank you so much again!!
Gabriela Marin
Hi Gabriela, That’s certainly possible, especially if you have collinearity among your predictors. However, scaling everything–including the dependent variable–will return already ‘standardized’ regression coefficients and not the raw coefficients. As Jim Grace suggests reporting both (as there is useful information to be had from each), this would back you into the corner of only being able to discuss your model coefficients in units of standard deviations of the mean. In both the current and development versions of the package, `standardize = “scale”` will either apply the scaling to the variables (version 1.0) or work from the existing Betasa (version 2.0). I would recommend keeping the variables in raw units if you can, and reporting both sets of coefficients. HTH, Jon
Hi Jon,
I have a technical question about calculating d-separation using piecewiseSEM. I ran into this issue because I was getting different values when manually calculating the C-statistic for my own models.
From what I understand, filter.exogenous() in piecewiseSEM filters out exogenous variables with no parents, because the direction of causality cannot be inferred from the model list. For example, if we fit a model based on the y-shaped model in Figure 3 above, x1 and x2 are both exogenous variables with no parents and would be removed by filter.exogenous(). However, doing this would involve leaving out one of the p-values used in the calculation of C.
Am I missing something here?
Many thanks!
Sam
Hi Sam, Correct, `piecewiseSEM` filters out pairs of exogenous variables because the direction of causality and the assumptions associated with the variables are unclear/unspecified. You could use the output from the d-sep tests and then conduct your own tests for the exogenous variables, and compute Fisher’s C by hand. The new version also allows you to add claims/P-values–see https://github.com/jslefche/piecewiseSEM/tree/2.0. The argument is supplied to `?summary.psem` Cheers, Jon
Hi Jon,
Thanks for the quick reply! I’ll have to go back and read through Shipley (2000) to figure out whether exogenous variables “should” be included in calculating Fisher’s C, and then figure out the direction of causality that I should test.
Thanks,
Sam
Alas, there’s no real consensus on this point. Shipley suggests that they should be incorporated. I argue they should not, for a lot of reasons: 1) they may not be any expectation of causality (e.g., windspeed and temperature), which is different than testing whether causal paths ought to have been excluded; (2) the potential direction of the test is unclear (not a problem for normally-distributed variables, a big issue for non-normally distributed ones); 3) practically, there is no way for the user to specify the assumptions of these relationships (not a problem if linear and Gaussian, a big issue for hierarchical, non-linear responses). There is a way to add claims to the basis set: drop me an email if you are still interested in doing so! Cheers, Jon
Hi Jon,
Thanks a lot for this amazing introduction to SEM. I am working on a simple SEM that includes one response variable and three explanatory variables. Given the small size of it, all variables are linked, leading to a fully saturated model. Dropping any link between variables would go against our ecological understanding of the system. I have been trying to figure out if using a fully saturated model is acceptable given that we can’t really test how well the model fits the data and I can’t really find a convincing answer either way.
What is your take on this issue?
Thanks a lot!
Mélanie
Hi Melanie, Yes a fully saturated model is fine if it reflects the data. You will not be able to obtain a Fisher’s C statistic (or a Chi-squared statistic in lavaan). In lieu of these, I recommend looking at the individual model R^2 to qualitatively assess how well each endogenous variable in your model is predicted. If all are high, then you probably have some high degree of confidence that your model reflects the data. Remember these values are influenced by model complexity (i.e., the number of predictors) so keep that in mind. Drop me an email if you want to discuss further! Cheers, Jon
Hi Jon, I am working on a SEM that includes one response variable (N2O emissions (KgN/ha*año) and eighteen explanatory variables. I have a categorical variable (dummy) that I want to include in the sem model. This variable is 0/1 (natural / crops)
I looking for a function in “piecewiseSEM package” but I have not found it. I saw the “jutila example” and it says
#Specifying grouping in summary
summary(jutila.sem, groups = “grazed”)
I wrote the same sentences in R, but the results were
Length class Mode
18 lme list
18 lme list
18 lme list
1 glmerMod s4
Could you help me ??
Thanks a lot !!!
Nuria
Hi Nuria, For the moment the groups argument has been disabled. We are working on a better, more correct implementation. In the mean time, I would consider specify dummy as a binary variable and using GLM. Email me if you run into trouble! Cheers, Jon
Thanks Jon !!!
Hi Jon,
Thanks for all your detailed info and explanations on piecewise SEM’s
I am using your ‘piecewiseSEM’ package in R for my PhD research, and am worried that I likely have too many variables for the number of replicates I have.
The model is running fine, passes the goodness-of-fit test, component models have decent marginal and conditional R^2 values, and several ‘significant’ paths.
However, I only have 27 replicates and I am currently including 5 exogenous and 4 endogenous variables. In terms of the “d-rule”, does d = #endogenous variables + #exogenous variables? I can easily prune 1 endogenous variable and 2 exogenous variables if I am indeed violating the d-rule.
Thanks for any help!
Hi Kevin, Shipley suggests that the piecewise approach is more flexible for small datasets, because you need only the power to fit each model (and not the entire vcov matrix). The issue is that you may end up with a ‘good-fitting’ model with no explanatory power. If you have a model that runs, fits well, AND is useful for inference (i.e., high % variance explained, significant coefficients) then I say move forward with that model! Cheers, Jon
Thank you, Jon!
Hi Jon,
This site has been extremely useful as I try to figure my way through SEM! I’ve been reading through several of the above comments, and they have been tremendously helpful as I work through my model. However, one issue I am running into that I don’t think has been previously addressed (I apologize if it has), is trying to include random and nested variables. I’m using the lme() function to try to account for the fact I have a random variable of species nested within sites. When I run the individual lines of code, I get no warning. However, when I run the whole model and sem.fit() I get an error saying
“nlminb problem, convergence error code = 1
message = false convergence (8)”
I’ve search this error and also can’t seem to come to a clear consensus. Do you have any thoughts on what might be causing this?
Hi Danielle, Yes this is not uncommon. The issue is that your models in your SEM converge, but the same models don’t when evaluating the independence claims. Imagine you have a -> b -> c. The one independence claim is a -> c. That is the model that is failing. One way to get around this in `lme` is to revert to the old optimizer. Add the argument:
control = lmeControl(opt = "optim")to your models and see if that helps! Cheers, JonHi again, Jon!
I’m having a hard time to understand coefficients and the relation between variables in the piecewise model when variables are not normally distributed. Can you help me out?
Imagine the model:
C ~ aA + bB (poisson distribution with log-link function)
B ~ dA (poisson distribution with log-link function)
Usually in SEM models, to calculate the effect A has on C, we should calculate: d*b + a. However, due to the link-function, this influence should be (using R notation for euler^):
B = exp(intercept + d*A)
C = exp( intercept’ + a*A + b*B)
= exp( intercept’ + a*A + b* exp(intercept + d*A))
In this case, I understand the direct effect A has on C is a, but how multiplying b*d express the indirect effect? Doesn’t it ignore the intercept of the first model or ignore the fact that d in the exponential term?
Another thing:
If that way of concatenating the models is correct, then it is possible to write C in function of A (as it is done above, and it would possible to predict the value of C for a range of values of A and see the effect A has on C, but it would not be possible to know the indirect effect.
So basically, my questions are:
Is the way I expressed the concatenated models correct?
If so, is it still possible to multiply the coefficients as it is usually done in normal distributed SEM (d*b + a)?
If it is not, how can I know the indirect effect?
Thank you very much again!
Hi Gabriela, No, at the moment its not possible to compute the indirect effect for non-Gaussian responses but if you install the development version of the package () you’ll find we’ve implemented some new standardization methods that might help. See
?coefsonce you install or read section 3 of the vignette. Cheers, JonHey Jon,
I’m curious about trying to evaluate my data using piecewiseSEM. I have 3 categorical predictor variables (all two levels) and two covariates (one categorical with two levels and one continuous). I have 3 responses variables. My data are nested, thus I have run traditional linear mixed effects analyses separately for each response using the ‘lme’ function in ‘nlme’ package. I found evidence of interactions among my predictors and covariates. My goal now is to further tease apart the direct effects of my predictors and covariates from the indirect effects of my response variables on each other. This seems like a good situation for piecewiseSEM, but I’m having some trouble doing the analyses. I have fit a group of mixed effects models (‘lme’) and passed those to ‘sem.fit’ following my hypothesized effects of each predictor on each response. I am also using the ‘sem.plot’ function to try and understand how my model structures are being evaluated by ‘sem.fit and reported by ‘sem.coefs’. This is where I’m getting tripped up. It appears that red lines represent negative relationships and black lines represent positive. I thought that transparent lines represented non-significant effects, but sometimes significant effects are transparent and sometimes significant effects are not represented by a line between variables at all. Plus, sometimes there are dashed lines that I’m not able to interpret. This leads me to believe that I don’t fully understand how ‘sem.fit’ is evaluating my model list and how best to build my model list to answer my questions. So, my questions are:
1) Does piecewiseSEM handle multiple categorical predictors? and 3 response variables?
2) How should I include multiple predictors and interactions in my model list? Currently I’m representing multiple predictors and interactions as you would in a traditional mixed model
e.g.: a,b,c = predictors, d=categorical covariate, e=continuous covariate
modlist<-list(
lme(response1~a+b+c+d+e+a*b+a*c+b*c+a*d+a*e, random=~1|site, mydata)
lme(response2~response1+a+b+d+e+a*b, random=~1|site, mydata)
lme(response3~response2, random=~1|site, mydata)
)
3) Is question #2 related to how I interpret the line types generated by 'sem.plot'? i.e., conditional effects vs interactions?
5) What is being reported by 'sem.coefs' when I have multiple variables and interactions included in each model in my model list passed to 'sem.fit'.
I'm guessing my problem lies with the way I am specifying my models in my model list, i.e., strings of conditional responses greater than 1 and interactions.
Thanks in advance,
Anthony
Hi Anthony, Lots to unpack here. First off, I recommend using the development version of the package, found here: The functionality is greatly improved and its much more reliable. I will note that the
sem.plotfunction has not yet been ported for lots of good reasons. Re: your questions1) Sort of. At the moment, the coefficients are returned but you will get errors. They will of course be relative to the reference level as well. We are working on an approach that returns marginal means for all levels of categorical predictors, but that is medium priority right now.
2) Without knowing your data or hypotheses, those are a LOT of interactions. I am most concerned about interactions between continuous and categorical variables. Depending on what the covariate d is, this is getting into multigroup model territory. We are also working on that implementation but have prioritized other aspects of the functionality right now. If you are interested in testing the differences among coefficients for each level of d and not specifically their interactions, drop me an email.
3) I would ignore that output, sorry, its just not a very functional. Plotting SEMs in R has always proven to be difficult.
5) The output is the raw (unstandardized coefficient), its standard error, d.f., significance value, and standardized coefficient. The default standardization for continuous variables is scaled by standard deviations of the mean. I imagine you get an error with the categorical interactions. Its not clear how and whether those ought to be standardized. Unfortunately you are hitting up against the bleeding edge of structural models. If you want to discuss options, again shoot me an email and we can hash it out.
Cheers, Jon
Hi Jon,
Sometimes papers just take longer than expected. 😉 I’m still at work on an SEM for data that I asked you about in 2016 related to oil and gas noise (noise), human disturbance (perdisturb_5km), proportion sagebrush (propsage800m) and the binomial response, which is represented by whether sage-grouse populations are declining at leks (PopFactor). I have a refined model that looks like this:
mydf.sem = psem(
lm(NOISE ~ PERDISTURB_5KM , data = mydf),
lm(PROPSAGE800M ~ PERDIST800M, data = mydf),
glm(PopFactor ~ NOISE + PROPSAGE800M, data = mydf, family=binomial(link=”logit”))
)
summary (mydf.sem) ### Evaluate fit
My question is about determining best model fit, specifically in the case where there is a covariate that has multiple buffer distances to choose between. In this case, my question relates to the covariate representing disturbance (PERDISTURB_5KM in the model above). Following methods described in Riginos and Grace (2008), I ran bivariate correlations between disturbance and noise for all the buffer distances that I had (800m, 1600m, 2000m, 5000m). The strongest correlation was between disturbance at 5km and noise, so I proceeded using that distance in all my SEM models. FYI, I selected PropSage800m distance based on best fit correlations with PopFactor.
However, when I tested the model above and changed only disturbance at different buffer distances, the best overall model via lowest AIC and Fisher’s C was the model with disturbance at 800m, not the one at 5km.
My question to you is which approach you recommend I take to determine best model fit: 1) based on individual correlation between disturbance and noise, 2) based on overall model fit via AIC and Fisher’s C or 3) A coauthor suggested I could test correlation between disturbance and the binomial response (PopFactor) to guide disturbance buffer distance selection.
I’d greatly appreciate any thoughts on have on this model selection question.
Best,
Holly
Hello Jon!
Thanks for this package! It´s usefull.
I´m still on at work on an SEM and i am getting a value of P=1 and a Fisher=0.
Should i understand this values like something is not working well? It´s infrequent get this extreme values, isn´t it?
Thanks for your time.
Its likely your model is just identified, meaning you have specified all possible linkages. Is this the case?
Hello Jon!
Yes, it is the case. Now i will try to explain why i have to speciefied all possible links.
My SEM have the following structure:
X1->X2->Y.
If i run that structure, the values are P=0.052 and Fisher=5.89 on 2 degree of freedom with a missing path: X1->Y.
So, i add the missing path and i get P=1, Fisher=0 on 0 degree of freedom
Just there is the piont where i doubt about my model. When a get P=1, Fisher=0 on 0 degree of freedom.
What do you think about?
Thanks for your help again!
Yes, the P = 1 and Fisher = 0 implies you have no missing paths. I recommend you read up on the tests of directed separation to understand why the test returns these values: its not necessarily a bad thing, just you aren’t able to report goodness-of-fit statistics. HTH, Jon
Hi Jon,
Thanks for all your work on a great package. I see from a previous post (from Kenji Yoshino, August 24, 2017) that version 1.2.1 was able to work with quantile regression (package ‘quantreg’). The current version of piecewiseSEM doesn’t seem to have that capacity. Do you have any plans to include this in any future versions? I’d love to be able to model quantiles rather than means.
Thanks a lot! Calum
Unfortunately quantreg is no longer supported in version 2.0 but I hope to restore it in the future. Right now there is no target date, but happy to help you execute it by hand! Cheers, Jon
Hi Jon,
I’m trying to figure the meaning of some errors I’m getting in my piecewiseSEM analysis. Here is the case: my response variables (03) are non-normally distributed; predictor variables include categorical (with more than two levels) and quantitative (count data and continuous) variables; two endogenous variables are correlated.
glmsem1 warnings()
Warning messages:
1: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
2: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
3: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
4: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
5: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
6: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
7: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
8: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
9: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
10: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
11: In B * (sd.x/sd.y) :
longer object length is not a multiple of shorter object length
12: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
13: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
14: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
15: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
16: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
17: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
18: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
19: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
20: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
21: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
22: In B * (sd.x/sd.y) :
longer object length is not a multiple of shorter object length
23: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
24: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
25: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
26: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
27: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
28: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
29: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
30: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
31: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
32: In var(if (is.vector(x) || is.factor(x)) x else as.double(x), … :
NAs introduced by coercion
33: In B * (sd.x/sd.y) :
longer object length is not a multiple of shorter object length
In addition to theses error messages, I have noticed that the test of directed separation show only ONE independence claim. See below
˜
Tests of directed separation:
Independ.Claim Estimate Std.Error DF Crit.Value P.Value
Y1 ~ X + … -0.0065 0.0224 469 -0.2913 0.7709
Global goodness-of-fit:
Fisher’s C = 0.521 with P-value = 0.771 and on 2 degrees of freedom
OR below with warning message at the end
> summary(glmsem1, .progressBar = F)$dTable
Independ.Claim Estimate Std.Error DF Crit.Value P.Value
1 Y1 ~ X + … -0.0065 0.0224 469 -0.2913 0.7709
There were 33 warnings (use warnings() to see them)
The one involving Y3 (which is my variable of interest) is missing. The meta-model is supported theoretical underpinning though. My question is what should I understand?
Second issue: when I tried to extract the standardized coefficients using the syntax below, I got only NAs
> coefs(glmsem1, standardize.type = “latent.linear”)
Std.Estimate
1 NA
2 NA
3 NA
4 NA
5 NA
6 NA *
7 NA
……
I suspect it might be because of the mix of different type of variables, particularly categorical (multinomial) variables as predictors…What do you think?
Thanks in Advance,
Alcade
Hi Jon!
Thank you again for your package!! I was using the previous version and now I am trying to rerun the analysis in the new version, but I am getting some new error messages and I cannot find out what they mean. I was hopping you could help me.
First, we have pretty complex models with different distributions and link-function within the model plus random factor. I have seen the new version is better prepared to deal with different link functions to test d-sep, but I am having trouble to use model with gaussian (logit) distribution + random factor. Whenever I use these two characteristics together, I get the following error after the summary(, conserve=T) command: Error in rsquared.glmerMod(i, method) : Unsupported family!
I’ve done some tests and this error only occur with gaussian(logit) + random. I‘ve even tried to run binomial + random (just out of curiosity) and I get no error. Using the old commands from the first version works just fine. Do you have any ideia about what is happening or any recommendation?
Second, as I was doing multiple combinations, whenever I didn’t get the error message (e.g. using binomial distribution), I continued adding important and meaningful paths and then the second error message occurred:
Error in (function (…, row.names = NULL, check.rows = FALSE, check.names = TRUE, : arguments imply differing number of rows: 3, 2
This seems to be some data.frame issue and I am clueless as to what does it means inside your package. This error appeared after I modified a very simple model: lmer(x ~ y1 + (1|random),data), by adding a new fixed continuous variable (y2). It has something to do with the random factor because if I exclude the radom factor, it runs just fine. Again, do you have any idea why this is happening? Any recommendation? In all tests I ran, when using the old functions (still available in the new package, but not recommended), I got no error message and whenever it was possible to compare results, I got the same results and coefficients values, but slightly different AIC and Fischer-C values (the same qualitative result, though). Does this mean anything? Could I use the old functions in these cases that I get these weird error messages?
Since I am already writing to you, is there other ways to check for model fit besides AIC and FischerC in piecewise SEM? I know it is common in SEM to present multiple global fit metrics (X2, RMSEA, CFI…) and I’ve been asked to do the same in our model, but I can’t find if there is other applicable measures (besides local fit measures such as coefs, SE, pseudo-R2) to evaluate fit in piecewise.
Hi Jon,
Do you have any suggestions for how to include a path with non-random missing data (i.e. because one of the endogenous variables is binary survival (0,1)? It would be great to determine if the mechanism of the treatment affecting survival is directly through Treatment effects on Survival (Binomial) or mediated through changes to AMF colonization (Gaussian) that then determines Survival. The trouble is I can only measure AMF colonization in the surviving plants. I realize this is not specifically a piecewiseSEM question, but I wonder if there are any particular strategies to include or exclude missing data (from the plants that did not survive) under this framework.
m1<-glm(Survival ~Treatment + AMF, family = binomial(link = "logit"))
m2<-lm(AMF~Treatment)