
I’ve been hacking away at this post for a while now, for a few reasons. First, I’m a git novice, so I’m still trying to learn my way around the software. Second, this is an intimidating topic for those who are not used to things like the command line, so it was a challenge to identify which ideas were critical to cover, and which could be ignored without too much of a loss in functionality. Finally, there are always lots of little kinks to work out, especially in a software that is cross-platform. Therefore, please take the following with a grain of salt and let me know if anything is unclear, needs work, or is flat out wrong!
First, a brief introduction:
What is version control?
Version control is a system that keeps track of changes to files over time. It can be implemented singly or collaboratively, but It’s most useful for large projects where multiple people are making changes to big datasets and running complicated, multipart analyses.
Why should I use version control?
Version control allows you to revert files back to a previous state, revert your entire project back to a previous state, and review changes made since the beginning of your project. In other words, it’s like a giant timeline for your project that you can interact with, undoing changes at any point in time. The benefits of such a system almost go without saying: recovering original or updated copies of accidentally deleted files or scripts, understanding when and why changes were implemented and by whom, being able to cite and replicate your workflow in its entirety.
Collaboratively, version control allows you to see who within your group introduced changes to what and when. It’s also a powerful tool for merging multiple copies of files if more than one person has modified them, making assigning separate tasks and then collating and integrating changes much easier.
There are a few posts at StackOverflow that elaborate a bit more on the utility of version control. Check them out here and here.
What is git?
Git is a popular software that utilizes a distributed approach to version control. In centralized models, files are stored on a single server that is accessed by project participants remotely. Git actually clones the entire project from the server to each individual participant’s computer, meaning that everyone has a local backup of the entire project (and its history) at any given time and can access/modify it even if a centralized server goes down.
Git also takes a slightly different approach to version control. In other version control systems, projects are stored as a set of files and the changes made to them over time. In git, the entire project is stored as a series of “snapshots.” So unlike other version control systems, in git, files that remain unchanged are represented in each snapshot along with a list of all the modifications from the previous snapshot.* This makes it easy to revert to a given point in time, as opposed to undoing changes made to individual files, which could get messy.
*For those worried about space, snapshots are not full copies. Often they simply link back to the unmodified file or log changes that can be extracted from files to revert them to a previous state.
How do you use git?
In git, project files and snapshots are stored in a “repository.” Typically, this is hosted on a server for easy distribution to other participants, but in the example below, I show how to create a local repository (aka just on your computer) for individual projects. Another option is to host a repository on a service like GitHub. Participants clone a local copy of the repository that they can modify. After the repository has been cloned, participants “pull” changes from the server (such as those committed by other participants) to their local git directory, and “push” their own changes out to the server. By pulling all the modifications others have pushed, everyone has the most up-to-date versions of files locally and all changes are backed on the server.
Git utilizes the the Bash scripting language to clone, push to, and pull the git repository. For Mac and Linux systems, Bash scripts can be run through the terminal. Windows users have to install a Bash shell (it comes bundled with git). A quick search will show how to implement these operations in the command line, but in the interest of playing to the less tech savvy, the fantastic R Studio has a more user-friendly version of git that is super easy to use, if not a little buggy. In that vein, I’ll highlight a few useful lines of code I find useful when R Studio hangs or does something quirky.
– – – –
I recently discovered that my favorite R GUI, R Studio, integrates nicely with git. I’ve written a basic tutorial to using git in R Studio in an effort to get collaborators and labmates on board using software they are familiar with (R Studio).h
Version Control Using Git and R Studio
1. First, install R Studio from here. If you’re not using R Studio, you should be. Not only is it an intuitive GUI for R, but it has a lot of great integrated features (such as version control) that are unavailable in other R GUIs.
2. Second, install git from here. Again, Windows users will have the Bash shell bundled with the git installer. Choose all the default options.
2a. Before getting started with R Studio, Windows users will have to jump through a few more hoops. First, you need to point your OS to the git executable (git.exe). Go go to System Properties->Advanced System Settings->Environment Variables->select Path->Edit->add the path to the git executable and click OK. In my case (Windows 8.1 x64), the path was something like C:\Program Files (x86)\git\bin. Those of you running 32-bit Windows will have a path like: C:\Program Files\git\bin.
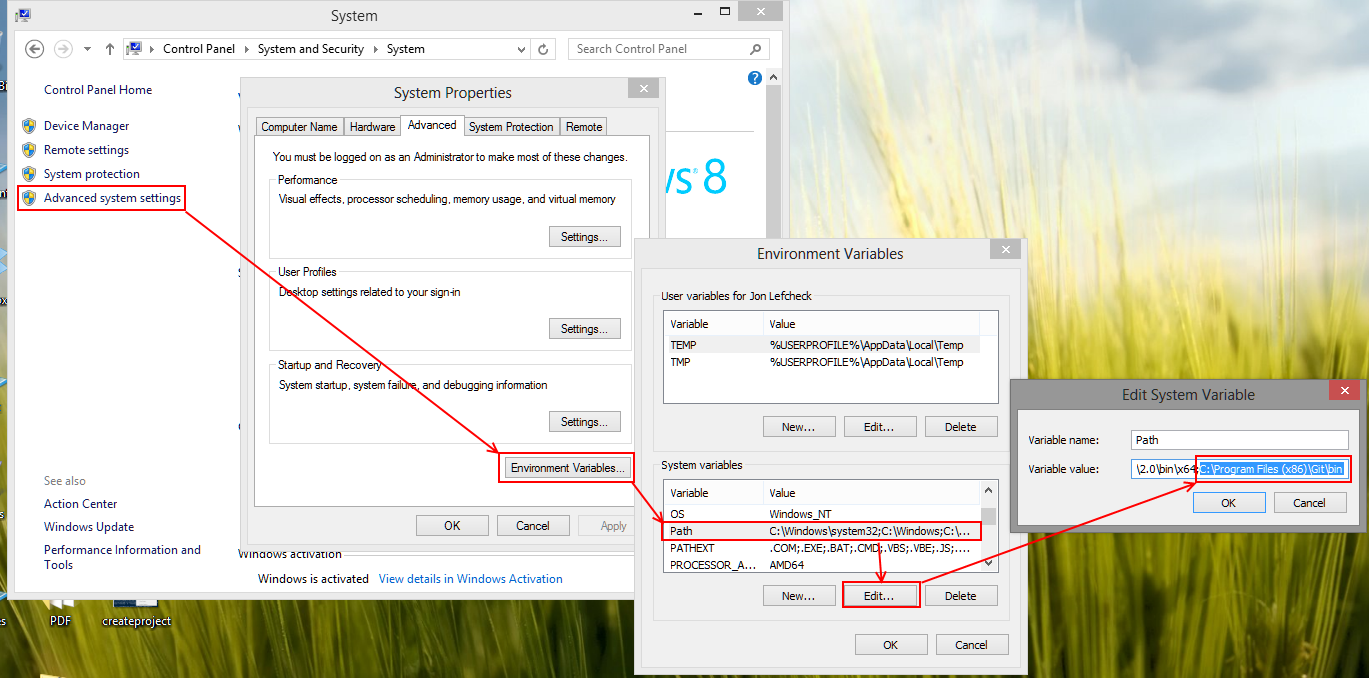 Now that you have pointed the OS to the git executable, you also need to specify the same location in R studio by going to
Now that you have pointed the OS to the git executable, you also need to specify the same location in R studio by going to Tools -> Options -> Git/SVN. Use the same path as above.

3. Now we can get down to business. R Studio uses “Projects” to integrate version control. To start a new project, open R Studio and navigate to “Create project.”
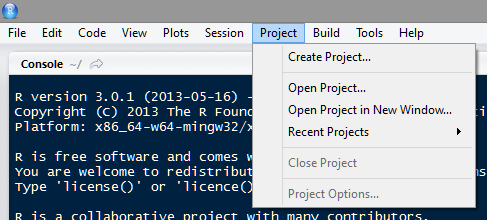 You need to point R Studio to a directory where the project files will be stored. This can be local, or hosted, or can be on a service like GitHub. and choosing “Version Control” in the menu.
You need to point R Studio to a directory where the project files will be stored. This can be local, or hosted, or can be on a service like GitHub. and choosing “Version Control” in the menu.
 For this example, I just created a local repository by choosing “New Project,” making sure that “Create a git repository for this project” is checked. Make sure to specify the correct subdirectory (i.e., where you want to store the project on your computer). For a little extra redundancy, I tossed my project files into a Dropbox folder.
For this example, I just created a local repository by choosing “New Project,” making sure that “Create a git repository for this project” is checked. Make sure to specify the correct subdirectory (i.e., where you want to store the project on your computer). For a little extra redundancy, I tossed my project files into a Dropbox folder.
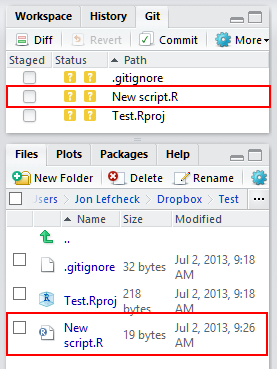
 4. Now create a new R script (I called mine “New script.R”). You will see the file appear in the Files tab in the lower righthand pane, as well as in the git tab next to the Workspace tab in the upper righthand pane.
4. Now create a new R script (I called mine “New script.R”). You will see the file appear in the Files tab in the lower righthand pane, as well as in the git tab next to the Workspace tab in the upper righthand pane.
 4a. Before committing any changes, its necessary to let git know who you are. You can set up your username and user e-mail using the command line.
4a. Before committing any changes, its necessary to let git know who you are. You can set up your username and user e-mail using the command line.
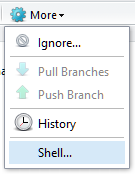 Click
Click More -> Shell -> and type:
git config --global user.email "you@example.com"
and:
git config --global user.name "Your Name"
This will allow anyone using the repository to track what changes have been made and by who.
5. Now we want to commit “New script.R” to the repository. Click the button in the “Staged” column next to “New Script.R.” The Status will change from “? ?” to “A” for accepted. Then click the “Commit” button.

You’ll notice a few other files. The .gitignore file is a list of files that can ignored (surprise). In other words, files listed here can never be committed. A good example would be the .Rproj file itself. You can fiddle with the .gitignore file, but best practice is not to commit either it or the .Rproj file.
Here is where things get a little hairy. I have found that R Studio sometimes doesn’t let me check staged (apparently this has something to do with spaces in file names), and I have to commit using the command line.
Nothing too bad: simply click on More-> Shell and type git status to check the unstaged changes. Then type git add "<filename>" (with the file name in quotes, especially if there are spaces–and let’s be honest, most people use spaces in their file names). Typing git status again shows the file is now staged. A handy tip: git add -u stages all unstaged files.
 To unstage a commit that has already been staged, but not committed, you can uncheck the box in R Studio or use the command
To unstage a commit that has already been staged, but not committed, you can uncheck the box in R Studio or use the command git reset HEAD <filename> with the filename in quotes.
6. Clicking the commit button in R studio will cause the commit dialogue box will pop up. Here, you can review changes to “New script.R.” You can also append a commit message, where you can detail any changes that were made to the file. When done, click “Commit” and a dialogue box will pop up confirming the commit and listing the changes.

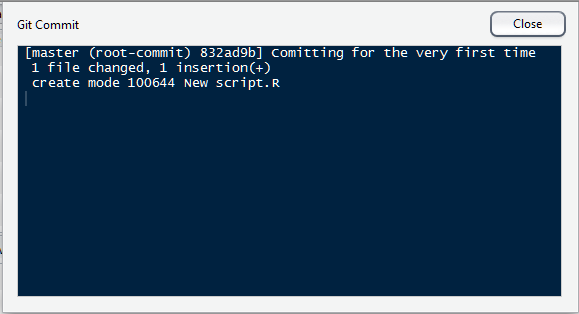 You can also commit from the command line. Surprise, its
You can also commit from the command line. Surprise, its git commit. This will bring up the commit dialogue. Type the commit message, then Esc :wq and press enter.
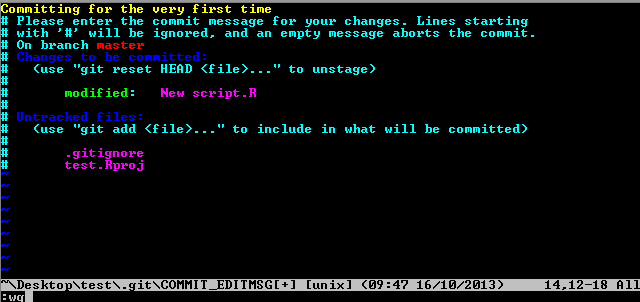 6a. The nice thing about R Studio is that it has a nice graphical visualization of commits. Simply click the “Commit” button and up pops the history window:
6a. The nice thing about R Studio is that it has a nice graphical visualization of commits. Simply click the “Commit” button and up pops the history window:
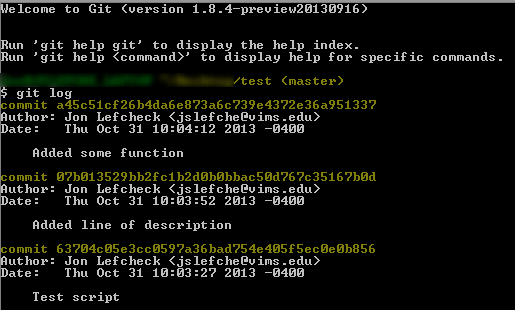
 You can do the same thing from the command line by typing
You can do the same thing from the command line by typing git log.
 6b. You will notice that any changes to the file after the initial commit will show the file as “Modified” with a little “M” Now, the key part. The file can be staged and committed as usual.
6b. You will notice that any changes to the file after the initial commit will show the file as “Modified” with a little “M” Now, the key part. The file can be staged and committed as usual.
 7. Now, the key part: to undo a commit, aka, revert back to a previous state.In R Studio, this is as simple as clicking “Revert.”
7. Now, the key part: to undo a commit, aka, revert back to a previous state.In R Studio, this is as simple as clicking “Revert.”
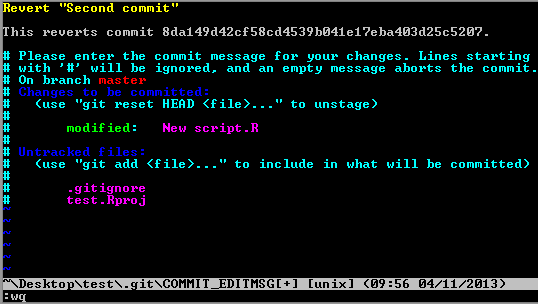
 In the command line, to revert to a previous commit, simply type
In the command line, to revert to a previous commit, simply type git revert head "<filename>" then the revert message, and finally Esc :wq and press enter. Typing git revert head will undo any changes to any files since the last commit.
 – – – –
– – – –
And that’s an extremely basic guide to git, including how to set up a local repository, stage and commit files, view the change history, and revert changes. I didn’t cover topics like .gitignore, branching and collaboration (including things like GitHub) in depth, but maybe down the road.

Hey! Do you use Twitter? I’d like to follow you if that would
be ok. I’m absolutely enjoying your blog
and look forward to new updates.
Great, thanks! You can follow me @jslefche but I’m afraid the blog updates will be far between for the next few months as I try and wrap up some manuscripts. I’ve got a few drafts in the pipeline, so there will be content coming eventually!